For this work I investigated the use of the DNC in the lifelong learning context. Lifelong learning differs from multi-task learning slightly. In multi-task learning, the goal is to learn multiple tasks simultaneously. In lifelong learning, the goal is to learn multiple tasks sequentially, without forgetting old tasks.
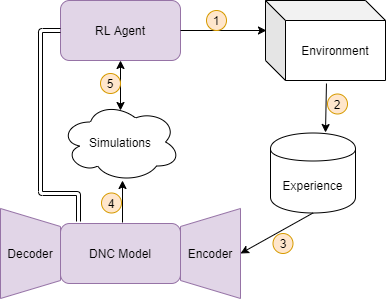
In the paper I introduced the Neural Computer Agent, where a model of the environment is learned by a DNC, and a paired agent is trained to maximize rewards using the Proximal Policy Optimization (PPO) algorithm in simulations generated by the DNC model.
Schematic for the iterative lifelong RL architecture, the Neural Computer Agent. An agent interacts with the environment to collect experience, which is used to train a predictive DNC model. The model is then used to simulate the environment to train the agent. The agent then rolls out to the environment again to collect new experience and iterate again.
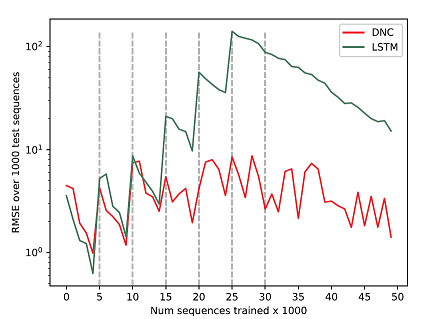
I hypothesized that the DNC can be used to learn a global model as opposed to task-specific local models which are used in multi-task and lifelong learning. I first tested the DNC on an integer addition task where the task progressively changed in difficulty, and found that the DNC can leverage past knowledge and adapt to new tasks quickly, outperforming LSTM by an order of magnitude. Additionally, the DNC continued to perform well on the prior learned integer addition tasks after it learned new ones.
DNC and LSTM performance over the course of training on multiple progressively difficult addition tasks. The curriculum steps switch at every 5, 000 sequences trained, until 30, 000 sequences, where the most difficult task remains fixed until training concludes.
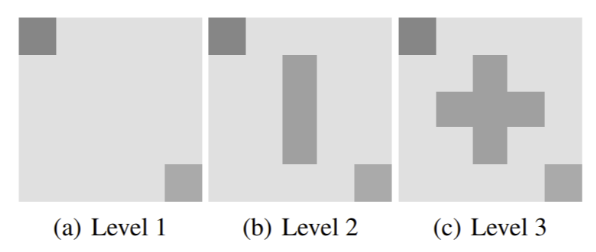
I tested The Neural Computer Agent on two toy RL environments that contained multiple tasks. I found that in both environments, the DNC was able to learn an adequate model of all tasks, and the Neural Computer Agent solved each environment iteratively entirely in simulations.
The levels (tasks) present in the Obstacle-Based Grid Navigation environment. The levels are designed to progressively increase in difficulty by adding obstacles. The agent starts at the top left cell of the grid, and has to reach the goal cell at the bottom right in a minimum number of steps.
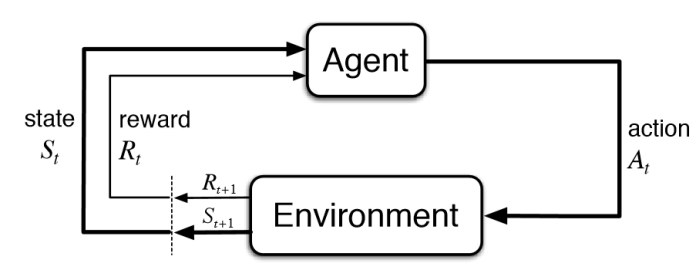
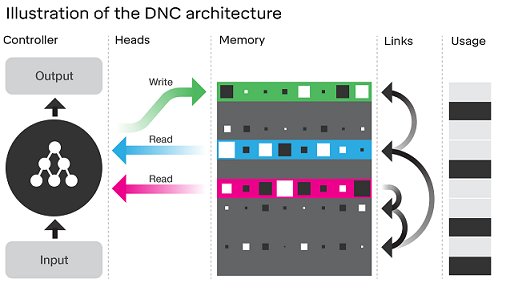
The DNC is a form of a memory augmented Neural Network that has shown promise on solving complex tasks that are difficult for traditional Neural Networks. When a Recurrent Neural Network (RNN) such as Long Short Term Memory (LSTM) is used in the DNC architecture, it has the capacity to solve and generalize well on tasks with long temporal dependencies across a sequences. At each timestep in a sequence, the DNC receives an external input, and memory data read from its internal read head mechanism from the previous timestep, to manipulate its internal state and produce the next output.
The external memory of the DNC also presents an additional mechanism to observe what the DNC is doing at each timestep. DeepMind did some evaluation of the memory contents in their original paper on Neural Turing Machines on some very structured problems it was trained on (such as copying), to infer it was learning algorithms as the memory contents recorded and moved information in structured ways.
In my previous work, I used DNCs for model-based Reinforcement Learning, where a model of video games was learned in the DNC. Features from this model were then used to train a controller to maximize its cumulative rewards in the video game. The features fed to the controller from the model were the hidden state [latex]h_t[/latex] and cell state [latex]c_t[/latex], of the LSTM in the model, at every timestep [latex]t[/latex], as done in the World Models framework.
I conjectured that the memory of the DNC used to train a model of the environment could contain useful information that could augment the the hidden and cell states of the LSTM being fed to a controller. At each timestep, the DNC contains the contents of its full memory ([latex]M_t[/latex]), portions of which are read by the read heads ([latex]r_t[/latex]) and used to produce the next output. Perhaps [latex]M_t[/latex] or [latex]r_t[/latex] contain useful information for the controller, especially if the video game contains very long term dependencies that need to be tracked as the game progresses.
Experiment Setup
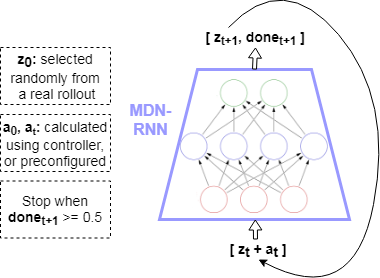
I decided to test what information is contained in the DNC’s memory at each timestep, when a predictive model of the environment is trained using a DNC as in the World Models framework. A “Model” in World Models is trained using Teacher Forcing, where the state of the game, z, at each timestep, along with an action, a, to be performed at that state, is given as input to the model. The model uses this information to predicts the next state. The state in this case is a compressed, “latent”, representation of the frame (image expressed as pixels) from the game at each timestep, created using a Convolutional Variational Autoencoder (CVAE). More specifically, the model receives input [latex][z_t + a_t][/latex] and produces output [latex]z_{t+1}[/latex].
As I found with my work on Probabilistic Model-Based Reinforcement Learning Using The Differentiable Neural Computer, DNC based models trained this way were able to outperform their vanilla LSTM (without external memory agumentation) counterparts. But, what is going on in the DNC’s external memory when it is trained this way? And furthermore, can this information be useful to a Reinforcement Learning or Evolution Strategies controller?
One way to test would be to check if the memory contained, linearly separable information about the current state. But to do so would require some discrete state labels of the video game for which a model was being learned, that could be used as ground truths. These states are not easily available or obvious when a model of the game is being learned from frames (images expressed as pixels) from live gameplay. Thus, with the help of a colleague, I formulated a toy task using DeepMind’s dSprites dataset.
dSprites consists of 737,280 total images that come from combinations of 5 different classes:
Shape: square, ellipse, heart
Scale: 6 values linearly spaced in [0.5, 1]
Orientation: 40 values in [0, 2 pi]
Position X: 32 values in [0, 1]
Position Y: 32 values in [0, 1]
Examples of randomly selected “sprites” from the dSprites dataset.
To train a predictive model using dSprites, I created rollouts to mimic what a video game would do. A rollout starts with a randomly selected sprite, and the “action” at each timestep provides information about the next sprite, also randomly selected (since this is not a real game). The actions correspond to the classes of the sprites, but more specifically, are the difference between the classes of the sprites from previous timesteps. If the classes of the sprites are represented at each timestep [latex]t[/latex] as [latex]\hat{a}_t[/latex], and the actual action provided to the model is represented as [latex]a_t[/latex], then [latex]a_t = \hat{a}_{t} – \hat{a}_{t-1}[/latex], where [latex]a_0 = 0[/latex]. As with the World Models teacher forcing training to learn a predictive model of the game, the state (the image of the current sprite) and action (classes delta to achieve the next sprite) are concatenated and input together to the model to predict (as output) the image of the next sprite. This setup allows the model to couple the state (the image of the sprite) with the action together to learn what the next sprite should be, rather than depending solely on the action if the action directly provided the classes of the next sprite, as that signal would be too strong and potentially cause the network to ignore the state input altogether.
As an example of the action inputs at each timestep, take our first randomly selected sprite to be [latex]\hat{a}_0[/latex] = [shape=1, scale=0.6, orientation=3.14, position_x=0.0625, position_y=0.0625]. The first input provided to the model would be the image of this sprite concatenated with action [latex]a_0[/latex] = [shape=0, scale=0, orientation=0, position_x=0, position_y=0] (by definition). Then, if the classes for the next randomly selected sprite are [latex]\hat{a}_1[/latex] = [shape=1, scale=0.7, orientation=0, position_x=0.125, position_y=0.125], the next action would be [latex]a_1 = \hat{a}_1 – \hat{a}_0[/latex] = [shape=0, scale=0.1, orientation=-3.14, position_x=0.0625, position_y=0.0625]. And so on.
Using this setup, rollouts of random length between 500 to 1000 were used to train the model, for 10,000 rollouts per epoch, for 5 epochs. Note that no CVAE or Mixture Density Network was used as is done in the World Models framework. This was to allow the model to be entirely deterministic, to make testing of memory more consistent.
Two variants of the DNC were trained, Model A and Model B:
Model A
Memory length
N = 256
Memory width
W = 64
Number of read heads
R = 4
Total memory size
16384
Read heads size
256
Model B
Memory length
N = 16
Memory width
W = 16
Number of read heads
R = 4
Total memory size
256
Read heads size
64
After training the DNC models, tests on the content of the memory were performed as follow. For each test, the model was run through 10,000 rollouts as described above, for a fixed sequence of length 500, and the contents of the full memory [latex]M_t[/latex] (in the case of Model B only) and contents of the read heads [latex]r_t[/latex] (both models), were logged at each timestep. Additionally, the full class label ground truths of the randomly selected sprites were logged at each timestep.
Test 1
This test was designed to check whether the logged full memory or read heads of the models contained information that could be used to infer the classes of the sprite at each timestep. As mentioned earlier, at each timestep, provided to the model as input are the current “state” which is the image of the current sprite, and the “action” which is the delta of the current sprite’s class label from the next randomly selected sprite’s class label, to allow the model to learn to use the two combined to predict the next state (the image of the next randomly selected sprite).
The test included checking whether at the current timestep, the memory contents could be used to infer the class labels of the current sprite being input. And whether it could be used to infer the class labels of past sprites it had already seen — 5 timesteps ago and 10 timesteps ago. Thus, each test was to check if the memory contained information about the class labels of the sprites presented at timesteps a) t-0, b) t-5, and c) t-10.
To do so, a simple single layer feedfroward neural network, without any activations, was used to train to use the memory contents (either full memory or just the read heads) at each timestep as input, to predict the class labels of the sprites at past timesteps as output. The point of doing it this way was to check whether the information being sought (the class labels) was clearly present in the memory by being linearly separable. It is inspired by the [latex]\beta[/latex]-VAE paper.
The neural network was trained using Softmax Cross Entropy loss for the shape class, and the Mean Squared Error loss on the scale, orientation, X position, and Y position classes. It was trained for a single epoch on the 10,000 rollouts with the logged memory contents at each timestep of the rollout sequence as inputs and class labels at each timestep of the rollout sequence as outputs. The Adam optimizer was used, with a minibatch size of 256. The inputs (the memory contents) were normalized by subtracting the mean and dividing by the standard deviation at each timestep.
After training, as this was a simple linear separability test to determine if the class labels could be easily inferred from the data, the same train set was used to test and compare the predicted classes with the ground truth classes using classification error for the shape label, and Mean Squared Error for the scale, orientation, X position, and Y position labels.
Test 2
The second test was designed to check whether if a pattern of “actions” (sprite classes) were given to the model in a predetermined sequence of length T (no longer of random length), if this pattern could be seen in the DNC’s external memory when logged and analyzed, using Mutual Information. The test involved running the model through a sequence of X positions, and this sequence was then checked using the mutual information score against each memory location by iterating over all memory locations and using the contents at that specific location over the timesteps.
For example, Model B had a full memory size of 256, which meant that each location in memory from 0 to 255 had some content, for every timestep from 0 to T of the input sequence the model was provided. If the X positions were fixed to be [0, 15, 30, 15, 0] (T=5), then first, memory location 0’s contents over the 5 timesteps, [?, ?, ?, ?, ?], were checked against the fixed X position sequence using mutual information score. Then memory location 1’s contents over the timesteps. And so on.
The point of this test was to check if the DNC had learned class representations of dSprites and was using the memory to track discrete information about the sprite’s classes — in this case, the X position of the sprites.
Results
Both DNC models were able to learn to predict the next state, i.e. the image of the next sprite, fairly well, based on visual inspection. Below, the real sprites are to the left, and predicted sprites to the right, from Model A. Note that the models are trained to output the full image of the sprite directly.
Ground Truths
Predictions from DNC Model A
Test 1
As a control, random inputs instead of the memory contents, were provided to the simple linear neural network model, but trained to predict the true labels. This linear model produced the following results:
Model A’s memory contents used were the read heads [latex]r_t[/latex] of size 256, and the simple linear model produced the following results in predicting the ground truth labels:
Model A Read Heads Results: shape classification error=0.5730384 scale mse=0.029882248834080166 orientation mse=3.454711805402036 position_x mse=0.02671479350697897 position_y mse=0.01284542320401027
Model B’s memory contents used were the full memory [latex]M_t[/latex] of size 256, and simple linear model produced the following results in predicting the ground truth labels:
Model B Full Memory Results: shape classification error=0.6396944 scale mse=0.02892420274878035 orientation mse=3.3985103721710175 position_x mse=0.08951739388579043 position_y mse=0.08840673772025909
Additionally, Model A was tested using the simple linear model trained on Model A’s read head contents at each timestep but instead using class labels from t-5 time steps ago and t-10 timesteps ago, to check if the memory contained information about past classes. Similarly, Model B was tested using the simple linear model trained on Model B’s full memory contents at each timestep. In both cases, the results were significantly worse than those listed above (i.e. predicting class labels at timestep t-0), and were close to the results from the random inputs, hence have been omitted from this post for brevity.
Test 2
For the second type of test, rollouts with all classes fixed except for the X position, were used as input. 50 sequences were created that randomly shifted the X position class between its 32 possible values, for a random length (number of timesteps in each rollout). These sequences of class labels were used as actions as described earlier, and the corresponding sprite images, were together fed as input to both Model A and Model B, and the content of the full memory [latex]M_t[/latex] at each timestep was logged. The memory content at each location within the memory was then tested to contain this predetermined sequence using the mutual information score
Additionally, during each of the 50 tests, a random sequence of class label inputs was created that was of the same length as the ground truth test sequence. This random sequence also ranged randomly between the 32 possible X position class values. The memory content at each location was also tested against this entirely random sequence, as a control.
For all sequences tested, contents at each location in the full memory were compared with the true test sequence for X position and the random control sequence. The mutual information score was roughly the same for both sequences, and less than 1e-8, for every memory location, thus showing virtually no mutual information in the memory contents.
Conclusions
The purpose of these experiments was to check when training a DNC to learn a predictive model of an environment such as a video game, whether the DNC’s external memory contained information about the states in the environment. The dSprites dataset was used to create a toy environment, as the sprites have class labels that can be used to map to discrete states the environment is in.
Test 1 was designed to check whether the full memory contents together, or the read head contents together, contained linearly separable information about the sprite classes being input at each timestep. However, in all experiments performed, the contents of the memory provided only very marginally better information in predicting the classes than when using random inputs instead of the memory contents. Model A’s read head contents performed slightly better than the random inputs compared to Model B’s full memory contents, particularly on the position classes. This points to a conjecture that perhaps the read head contents when training a DNC predictive model with a larger memory matrix can provide some useful information about the state of an environment. However, strong results should have seen significant improvement (lower errors, closer to zero) over predicting the states when using the memory contents compared to random inputs.
Test 2 was designed to check whether the DNC had learned some representation of the classes of dSprites when training a predictive model, and was using individual locations in the memory to track information about the states (classes) of the sprites being input. The tests showed that the DNC was not tracking the class that was tested, the X position, in any deterministic location in its memory, when using a mutual information score. In all tests, the score was close to zero, and no better than a random control sequence additionally tested at each memory location.
In future work, experiments could be performed to check whether the memory contains information about each individual classes in isolation. Also, perhaps the predictive model of the environment can be trained in a different manner such as with an augmented loss function, to bias the DNC in exposing more information about the state in its memory. Lastly, the Pygame Learning Environment has games where a discrete encoded state representation of the game can be queried at each timestep, and perhaps the DNC’s memory can similarly be tested on these environments as this representation gives labels for the states.
For my MSc Artificial Intelligence at the University of Edinburgh, my dissertation included 4 months of research. I investigated the use of the Differentiable Neural Computer (DNC) for model-based Reinforcement Learning / Evolution Strategies. A predictive, probabilistic model of the environment was learned in a DNC, and used to train a controller in video gaming environments to maximize rewards (score).
The difference between Reinforcement Learning (RL) and Evolution Strategies (ES) are detailed here. However, in this post and my dissertation, the two are used interchangeably as either is used to accomplish the same goal — given an environment (MDP or partially observable MDP), learn to maximize the cumulative rewards in the environment. The focus is rather on learning a model of the environment, which can be queried while training an ES or RL agent.
The authors of the DNC conducted some simple RL experiments using the DNC, given coded states. However, to the best of my knowledge, this is the first time the DNC was used in learning a model of the environment entirely from pixels, in order to train a complex RL or ES agent. The experiments I conducted showed the DNC outperforming Long Short Term Memory (LSTM) used similarly to learn a model of the environment.
Learning a Model
The model architecture is borrowed from the World Models framework (see my World Models implementation onGitHub). Given a state in an environment at timestep t, [latex]s_t[/latex], and an action [latex]a_t[/latex] performed at that state, the task of the model is to predict the next state [latex]s_{t+1}[/latex]. Thus the input to the model is [latex][s_t + a_t][/latex], which produces output (prediction) [latex]s_{t+1}[/latex]. Note that the states in this case consist of frames from the game at each timestep consisting of pixels. These states are compressed down to latent variables z using a Convolutional Variational Autoencoder (CVAE), therefore more specifically the model maps [latex][z_t + a_t] => z_{t+1}[/latex].
The model consists of a Recurrent Neural Network, such as LSTM, that outputs the parameters of a Mixture Density Model — in this cased, a mixture of Gaussians. This type of architecture is known as a Mixture Density Network (MDN), where a neural network is used to output the parameters of a Mixture Density Model. My blog post on MDNs goes into more details. When coupled with a Recurrent Neural Network (RNN), the architecture is known as MDN-RNN.
Thus, in learning a model of an environment, the output of the MDN-RNN “model” is not simply [latex]z_{t+1}[/latex], but the parameters of a Gaussian Mixture Model ([latex]\alpha, \mu, \sigma[/latex]) which are then used to sample the prediction of the next state [latex]z_{t+1}[/latex]. This allows the model to be more powerful by becoming probabilistic, and encode stochastic environments where the next state after a given state and action can be one of multiple.
For the experiments I conducted, the architecture of the model used a DNC where the RNN is used in World Models, thus, the model is composed of a MDN-DNC. Simply, the recurrent layers used in the MDN are replaced with a DNC (which itself contains recurrent layers that are additionally coupled with external memory).
The hypothesis was that using the DNC instead of vanilla RNNs such as LSTM, will allow for a more robust and algorithmic model of the environment to be learned, thus allowing the agent to perform better. This would particularly be true in complex environments with long term dependencies (meaning, a state perhaps hundreds or thousands of timesteps ago needs to be kept in context for another state down the line).
Experiments And Results
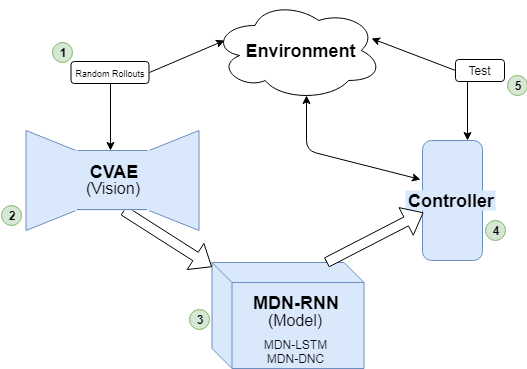
Experimentation schematic, based on the World Models framework.
The model of the environment learned is then used to train an RL agent. More specifically, features from the model are used, and in the case of the World Models framework, this consists of the hidden and cell states [latex]h_t, c_t[/latex] of the LSTM layers of the model at every timestep. These “features” of the model, coupled with the compressed latent representation of the environment state, z, at a given timestep t is used as input to a controller. Thus, the controller takes as input [latex][z_t + h_t + c_t][/latex] to output action [latex]a_t[/latex] to be taken to achieve a high reward. CMA-ES (more details in my blog post on CMA-ES in Python) was used to train the controller in my experiments.
The games the MDN-DNC was tested on were ViZDoom: Take Cover and Pommerman. For either game, a series of experiments were conducted to compare the results with a model of the environment learned in a MDN-DNC versus a MDN-LSTM.
ViZDoom: Take Cover
In the case of ViZDoom: Take Cover, a predictive model was trained in the environment using MDN-LSTM and MDN-DNC. Each was trained for 1 epoch, on random rollouts of 10,000 games which recorded the frames from the game (pixels) and actions taken at each timestep. The model was then used to train a CMA-ES controller. Note that the controllers were trained in the “dream” environment simulated by the model, as done in World Models.
A simulation of the environment — “dream” — where the controller is used to train using the learned model only, rather than the actual environment.
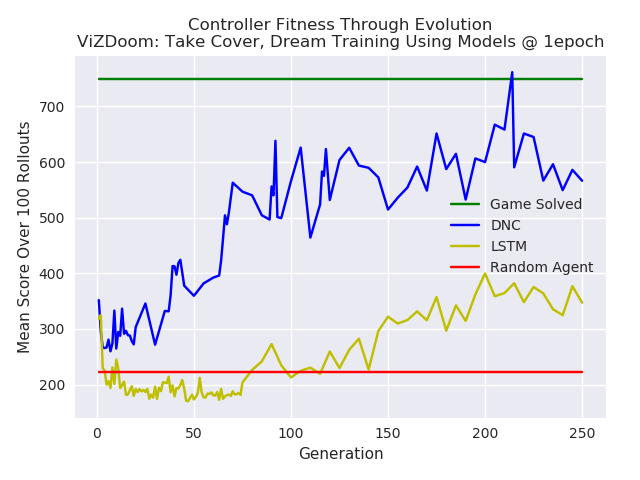
The controllers were tested in the environment throughout the generations for a 100 rollouts at each test. The results are plotted below. The MDN-DNC based controller clearly outperformed the MDN-LSTM based controller, and solved the game (achieving a mean score of 750 over 100 rollouts).
Comparison of a DNC based model versus a LSTM based model, used for training a controller in ViZDoom: Take Cover. The DNC based controller outperforms the LSTM controller.
Pommerman
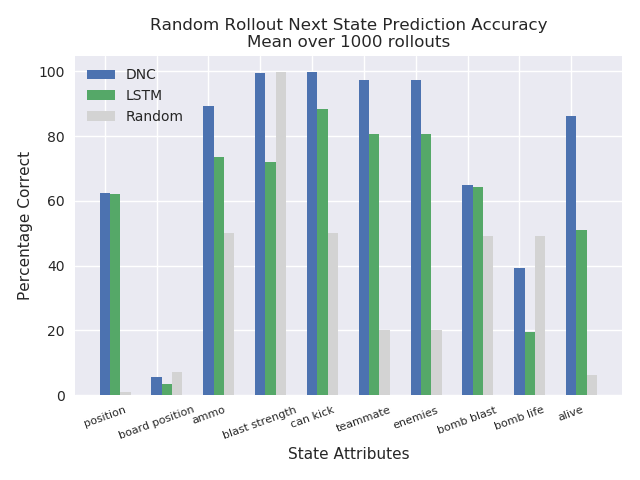
In the case of Pommerman, only the model’s predictions were used to test the capacity of the predictive model learned in a MDN-DNC and a MDN-LSTM. A controller was not trained. This was possible given that the states in Pommerman are coded as integers, rather than pixels. Thus, given [latex][s_t + a_t][/latex], the predicted state [latex][s_{t+1}][/latex] could be compared with the ground truth state from the actual game for equality, and to measure how many components of the state (position, ammo available, etc) were correctly predicted.
Here again, the MDN-DNC model outperformed the MDN-LSTM model, where both were trained exactly the same way for the same number of epochs. The MDN-DNC was more accurately able to predict the individual components of the next state given a current state and an action.
The predictive power of a DNC based model versus a LSTM based model in the Pommerman environment. The DNC based model was able to predict future states more accurately.
Conclusions
Model-based Reinforcement Learning or Evolution Strategies involve using a model of the environment when training a Reinforcement Learning or Evolution Strategies agent. In my case, the World Models approach to learn a predictive, probabilistic model of the environment in an Mixture Density Network was used. The Mixture Density Network consisted of a Differentiable Neural Computer, which output the parameters of a Gaussian mixture model that were used to sample the next state in a game. My experiments found that a model learned in a Differentiable Neural Computer outperformed a vanilla LSTM based model, on two gaming environments.
Future work should include games with long term memory dependencies, whereas with the experiments performed for this work it is hard to justify there being such dependencies in the ViZDoom: Take Cover and Pommerman environments. Other such environments would perhaps magnify the capabilities of the Differentiable Neural Computer. Also, what exactly is going on in the memory of the Differentiable Neural Computer at each timestep? It would be useful to know what it has learned, and perhaps features from the external memory of the Differentiable Neural Computer itself could be used when training a controller. For example, the Differentiable Neural Computer emits read heads, [latex]r_t[/latex], at each timestep, which are selected from the full memory, and used to produce the output (a prediction of the next state). Perhaps the contents of the read heads, or other portions of the external memory, could provide useful information of the environment if exposed directly to the controller along with the hidden state and cell state of the underlying LSTM.