➡ Implementation: https://github.com/AdeelMufti/RL-RND
Intrinsic Motivation is all the rage in Reinforcement Learning these days. In human psychology, intrinsic motivation refers to behavior that is driven by internal rewards. One example of intrinsic motivation is, if something new and usual is encountered, it may cause someone to give it more attention. In RL, a fine balance between exploration and exploitation is required. If exploration is inadequate, an agent may get stuck in a local optimum. This is particularly problematic if extrinsic rewards are sparse or not well defined. Thus, a mechanism for intrinsic motivation can be used to cause the agent to explore.
Enter Random Network Distillation (RND), as proposed by OpenAI:
https://openai.com/blog/reinforcement-learning-with-prediction-based-rewards/. In summary, a randomly initialized network — the target — is used to distill another network — the predictor — by training the predictor to learn the output of the target network given all states encountered so far as input. The measure of error between the target network and predictor network, can be used as a metric for intrinsic motivation when training a RL agent. As the target network and predictor network process states they repeatedly see while the RL agent does rollouts in the environment, the predictor network learns the target network’s reaction to the states, and thus the intrinsic reward becomes increasingly lower as the same state is seen again and again. However, if a new state is encountered, the predictor network would not be aligned with the target network on the new state, thus producing a spike in the error and increase in intrinsic motivation, allowing the agent to explore the new state encountered due to the higher rewards.
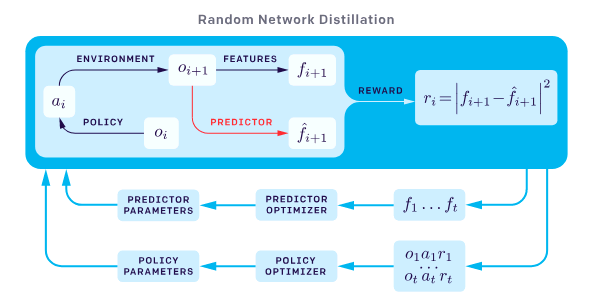
https://openai.com/blog/reinforcement-learning-with-prediction-based-rewards/).
I decided to create my own implementation in Chainer of a Proximal Policy Optimization (PPO) RL agent, to use intrinsic rewards through Random Network Distillation. I kept the implementation as close as possible to the details in OpenAI’s paper. The implementation can be seen at:
https://github.com/AdeelMufti/RL-RND.
I conducted an experiment with PixelCopter-v0, which I’ve been dealing with as a baseline task for a series of experiments involving Reinforcement Learning, Evolution Strategies, and Differentiable Neural Computers. I’ve noted that for several learning algorithms (CMA-ES, PPO, Policy Gradients), the agent easily and quickly falls into a local optimum. It goes up a few times (action = up), and then after that all actions are “no action”, until it falls on the floor and the game is over. This allows it to get a higher score than with random actions, but after that it never improves. When experimenting with PPO with RND for intrinsic motivation, I turned off the external rewards. Very interestingly, the agent fell into that exact local optimum, simply based on the intrinsic rewards!
As I conduct more experiments and adjust my implementation, I will be updating this post.