According to OpenAI, Evolution Strategies are a scalable alternative to Reinforcement Learning. Where Reinforcement Learning is a guess and check on the actions, Evolution Strategies are a guess and check on the model parameters themselves. A “population” of “mutations” to seed parameters is created, and all mutated parameters are checked for fitness, and the seed adjusted towards the mean of the fittest mutations. CMA-ES is a particular evolution strategy where the covariance matrix is adapted, to cast a wider net for the mutations, in an attempt to search for the solution.
To demonstrate, here is a toy problem. Consider a shifted Schaffer function with a global minimum (solution) at f(x=10,y=10):
[latex]f(x,y)=0.5+\frac{sin^{2}[(x-10)^{2}-(y-10)^{2}]-0.5}{[1+0.001[(x-10)^{2}+(y-10)^{2}]]^{2}},\ \ \ \ \ f(10,10)=0[/latex]
The fitness function F() for CMA-ES can be treated as the negative square error between the solution being tested, and the actual solution, against the Schaffer function:
[latex]F(s_1,s_2) = -(f(s_1,s_2) – f(10,10))^2[/latex]
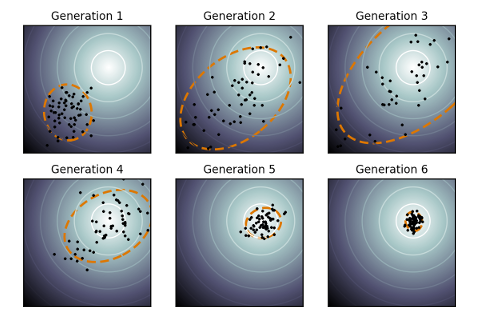
Therefore, the task for CMA-ES is to find the solution [latex](s_1=10, s_2=10)[/latex]. Given the right population size [latex]\lambda[/latex] and the right [latex]\mu[/latex] for CMA-ES, it eventually converges to a solution. With [latex]\lambda=64[/latex] and [latex]\mu=0.25[/latex], a visualization of CMA-ES as it evolves a population over generations can be seen below.
The animation below depicts how CMA-ES creates populations of parameters that are tested against the fitness function. The blue dot represents the solution. The red dots the entire population being tested. And the green dot the mean of the population as it evolves, which eventually fits the solution. You see the “net” the algorithm casts (the covariance matrix) from which the population is sampled, is adapted as it is further or closer to the solution based on the fitness score.
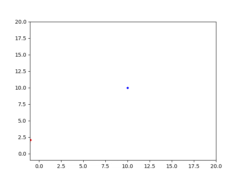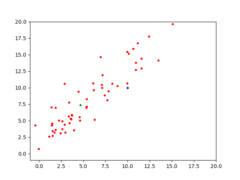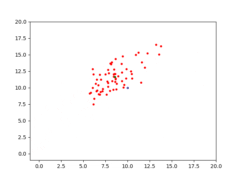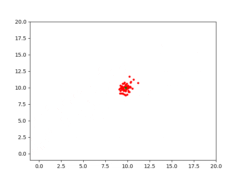
A simple (yet powerful) implementation for CMA-ES in Python, and this toy problem, is available at https://github.com/AdeelMufti/WorldModels/blob/master/toy/cma-es.py. I translated the (mu/mu_w, lambda)-CMA-ES algorithm to Python.