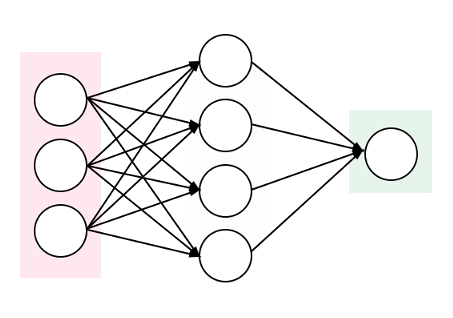
World Models is a framework described by David Ha and Jürgen Schmidhuber: https://arxiv.org/abs/1803.10122. The framework aims to train an AI agent that can perform well in virtual gaming environments. World Models consists of three main components: Vision (V), Model (M), and Controller (C).
World Models Schematic
As part of my MSc Artificial Intelligence dissertation at the University of Edinburgh, I implemented World Models from the ground up in Chainer. My implementation was picked up by Chainer and tweeted:
There are excellent blog posts and guides available on Mixture Density Networks, so I will not try to replicate the effort. This post provides a quick summary, and implementation code in the Chainer deep learning framework.
In summary, Mixture Density Networks are Neural Networks that output the parameters of a Mixture Model, such as a Gaussian Mixture Model, instead of the desired output itself. The Mixture Model is then sampled from to get the final output. This is particularly useful when given a certain input, there could be multiple outputs based on some probability.
The outputs from the neural network, in the case of Gaussian Mixture Models, include a set of probabilities [latex]\alpha[/latex] (coefficients), set of means [latex]\mu[/latex], and set of standard deviations [latex]\sigma[/latex]. For example, if output is y given an x, and you choose to have 3 Gaussian mixtures, the output of your neural network would be: [latex]\alpha_1, \alpha_2, \alpha_3, \mu_1, \mu_2, \mu_2, \sigma_1, \sigma_2, \sigma_3[/latex]. The [latex]\alpha[/latex] sum to 1 and represent the probability of each mixture being the likely candidate, and the [latex]\mu[/latex] and [latex]\sigma[/latex] represent the distribution of y within the given mixture and can be used to sample y.
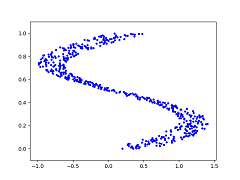
Take as a toy example consider the dataset of (x, y) coordinates represented in the graph below:
Toy dataset of (x, y) coordinates graphed.
The blue dots represent the desired y value given an x value. So at x=0.25, y could be {0, 0.5, 1} (roughly). In this case, training a neural network using Mean Squared Error to output y directly will cause the network to learn the average of the y values given x as inputs, as shown below (red dots represent y output from the neural network):
A neural network trained with Mean Squared Error produces an averaged output.
For this type of problem, a Mixture Density Network is perfectly suited. If trained properly, and sampled from enough times given all x values in the dataset, the Mixture Density Network produces the following y outputs. It better learns the distribution of the data:
A Mixture Density Network can learn the distribution of the data.
The output of the neural network is simply the number of dimensions in your output (1 in this example), times the number of desired mixtures, times 3 (the coefficient, mean, and standard distribution). In Chainer, a Linear layer can be used to output these numbers.
The loss function is essentially the negative log of the Gaussian equation multiplied by the softmax’d coefficients: [latex]-\ln\{\alpha\frac{1}{\sqrt{2\pi}\sigma}\exp{-\frac{(y-\mu)^2}{2\sigma^2}}\}[/latex], where [latex]\sum\alpha=1[/latex] [1]. This can be represented in Chainer easily as follows:
The default floating point size in Chainer is 32 bit. That means for deep learning, Chainer will expect numpy.float32 for CPU or cupy.float32 for GPU under the hood, and will exit with error if the data is set at a different size.
However, there may be times you want more than 32 bits, such as when you’re getting NaN’s or inf’s in your training routine and want to troubleshoot.
Changing Chainer to use float64 is simple:
import chainer
import numpy as np
chainer.global_config.dtype = np.float64
Call this at the beginning of your program. And of course, you’ll want to make sure that the ndarray dtype’s for your data are set to float64 (as in np.array(…).astype(np.float64)) before being passed to Chainer.
Chainer is my choice of framework when it comes to implementing Neural Networks. It makes working with and trouble shooting deep learning easy.
Printing out the gradients during back propagation to inspect their values is sometimes useful in deep learning, to see if your gradients are as expected and aren’t either exploding (numbers too large) or vanishing (numbers too small). Fortunately, this is easy to do in Chainer.
Chainer provides access to the parameters in your model, and for each parameter, you can check the gradient during the back propagation step, stored in the optimizer (such as SGD or Adam). To access these, you can extend chainer.training.updaters.StandardUpdater() to additionally output the gradients, by defining your own StandardUpdater like so:
class CustomStandardUpdater(chainer.training.updaters.StandardUpdater):
def __init__(self, train_iter, optimizer, device):
super(CustomStandardUpdater, self).__init__(
train_iter, optimizer, device=device)
def update_core(self):
super(CustomStandardUpdater, self).update_core()
optimizer = self.get_optimizer('main')
for name, param in optimizer.target.namedparams(include_uninit=False):
print(name, param.grad)
In lines 9-10 you can see the parameters (weights) of your neural network being accessed through the optimizer, and for each parameter, the name and gradient is being output. This StandardUpdater can be attached to your training module as follows: